De impact van datakwaliteit op het planningsproces

Door Jurgen Maas & Jan Veerman
Introductie
Data is overal om ons heen. Het genereren van data (privé en zakelijk) neemt een steeds grotere vlucht door de beschikbare techniek, waarmee de houders van deze data steeds meer inzichten verkrijgen en daar hun producten en dienstverlening op aanpassen. Het koppelen van data sets, het analyseren van deze data en het uitzetten van acties is belangrijker dan ooit en beïnvloedt daarmee steeds meer het plannings- en forecastproces binnen bedrijven.
Waar bedrijven traditioneel voornamelijk interne data gebruikten voor hun jaarlijkse planningsproces, staat het koppelen van externe databronnen om daarmee het plannings- en forecastproces te verrijken vaker op de agenda. Maar het vergaren en koppelen van data en het verkrijgen van inzichten is een lastige en tijdrovende taak, omdat de kwaliteit van de data altijd te wensen over laat.
Kosten van slechte datakwaliteit
Ervaring toont dat de meeste mensen in een organisatie de data niet vertrouwen. Ze hebben moeite met het begrijpen van de organisatiedata, omdat er geen duidelijke kwaliteitscontrole zichtbaar is op de data. De reden is onderdeel van een groter probleem binnen de organisatie, namelijk het ontbreken van een visie hoe om te gaan met (in- en externe) data, onderschatting van de kwaliteit van data op het plannings- en forecast proces en de (vaak verborgen) kosten van het beheer en onderhoud van data.
Verschillende onderzoeken tonen aan dat slechte data binnen de meeste organisaties een grote impact heeft op het kostenaspect binnen een organisatie. Het kostenaspect wordt onderverdeeld in twee categorieën:
? Kosten voor het opschonen en corrigeren.
? Kosten van incorrecte beslissingen.
De kosten van het opschonen en corrigeren van data worden voornamelijk gemaakt bij de bron. Veel tijd en effort wordt gestoken in het analyseren van de data, het vervaardigen van een rapport waaruit blijkt welke data niet voldoet en het (manueel) opschonen van deze data. Met als doel de kwaliteit van deze data bij de bron aan te pakken, om zo het vertrouwen in de kwaliteit te verhogen.
Voorbeelden van slechte datakwaliteit en dataprocessen binnen verschillende organisaties:
? Dezelfde (artikel)codes met verschillende omschrijvingen.
? Verschillende (artikel)codes met dezelfde omschrijvingen.
? Ontbrekende mapping, denk aan klantorder zonder een klant.
? Verschillende data definities in verschillende bronsystemen.
? Verschillende (master) data uit verschillende bronsystemen, maar onmogelijk te koppelen door ontbrekende logica.
? Processen voor het beheren (maken, bijwerken, verwijderen) zijn niet gestandaardiseerd en gebeurd op een ad-hoc basis.
? Er is geen “regelgeving” aanwezig omtrent data.
? Tijdsverschillen, denk aan verschillende updates op verschillende tijden die daarmee niet zijn gesynchroniseerd. Hierdoor ontstaat er inconsistentie.
De correctie van deze datakwaliteit is een arbeidsintensieve taak. De daarmee gepaard gaande kosten zijn voor een deel zichtbaar, maar voor een deel ook verborgen. Denk aan periodiek uitgevoerde activiteiten om de data weer te schonen, opschonen van data in Excel bestanden door gebruikers. Tijd die nuttiger besteed moet worden in de dagelijkse operatie. Naast het kosten aspect, heeft het ook een negatieve impact op de sfeer binnen de organisatie. Op het moment dat gebruikers de data niet vertrouwen en voortdurend met elkaar in discussie gaan over de juistheid van de data, is het moeilijker om dit vertrouwen terug te winnen.
Het tweede aspect van kosten, zijn de kosten van incorrecte beslissingen. Op het moment dat het management belangrijke beslissingen neemt, moet het blindelings kunnen vertrouwen op de kwaliteit van de data. Verkeerde data leidt tot verkeerde inzichten en daardoor foutieve beslissingen. Voorbeelden zijn het structureel te hoog inschatten van de klantvraag, waardoor er te veel voorraden worden aangehouden. Of een verkeerde investeringsbeslissing, die in de praktijk niet terugverdiend wordt. Het hebben van juiste data verhoogd de kwaliteit van beslissingen en reduceert (onnodige) kosten.
Aanpak voor verbetering van de datakwaliteit
Een veel gehoorde vraag waar organisatie mee worstelen is: “hoe de datakwaliteit te verhogen binnen onze organisatie?”. Gaan we dit eenmalig handmatig oplossen, doen we dit door middel van nieuwe software, gaan we zelf nieuwe software ontwikkelen? En als de kwaliteit is bereikt, hoe borgen we dan dat de data op het gewenste niveau blijft?
Het antwoord op deze vragen is vrij eenvoudig. Het begint bij een eerste identificatie in welke fase de organisatie staat aan de hand van het onderstaande model. Dit model is een weergaven van vijf verschillende levels, oplopend in de volwassenheid van de datastrategie.
Een eerste assessment geeft inzicht in het huidige niveau en het gewenste niveau. Let op: het is niet voor alle organisaties nodig om op level 5 uit te komen. Zelfs verschillende levels per (master)data binnen de organisatie is een optie, waarbij level 5 geldt voor de belangrijkste elementen.
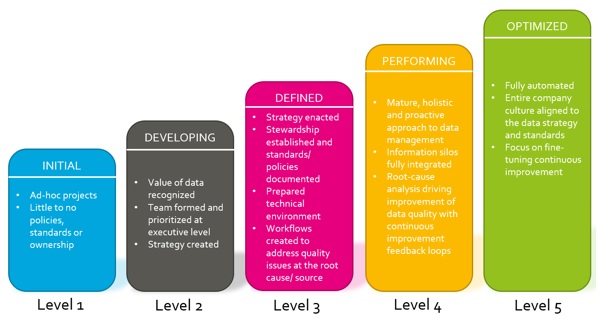
De vijf verschillende fasen van het model in meer detail:
1. Level 1: er is geen beleid omtrent datakwaliteit, standaardisatie en eigenaarschap van data binnen de organisatie. Projecten om de kwaliteit te verbeteren zijn vaak op ad-hoc basis en geen onderdeel van een groter programma.
2. Level 2: de organisatie erkent dat goede data belangrijk is. Er wordt een strategie ontwikkeld en geïmplementeerd, waarbij deze vanuit het managementniveau wordt ondersteund.
3. Level 3: de strategie is in werking gezet, data eigenaarschap is binnen de organisatie belegd en standaarden zijn gedocumenteerd. Nieuwe data generatie (bijvoorbeeld een nieuwe klant) wordt aan de hand van workflow binnen de organisatie gestroomlijnd om zo de kwaliteit te waarborgen.
4. Level 4: er is een volwassen en holistische aanpak met betrekking tot datamanagement. Data silo’s zijn verdwenen om zo de potentie van alle beschikbare data ten volle te benutten en er is een verbeteringsprogramma in werking die continue de kwaliteit van de data monitort om zo fouten bij de bron te pakken.
5. Level 5: de kwaliteit van de data wordt volledig automatisch beheerd, waarbij de kwaliteit van de data als onderdeel van de bedrijfscultuur is verankerd in het doen en laten van de medewerkers.
Een assessment geeft inzicht in het huidige en gewenste niveau. In deze assessment worden alle data gerelateerde processen en systemen onder de loep genomen. De eerste stap is het identificeren van alle databronnen en de bijbehorende data producenten (welk systeem of persoon genereerd de data) en de dataconsumenten (welke divisie, persoon of systeem heeft de data nodig). Deze matrix zorgt voor meer inzicht in de processen rondom data en hoe hiermee wordt omgegaan binnen de organisatie. De identificatie van slechte data wordt sneller herleid waardoor ingegrepen wordt om deze data te corrigeren.
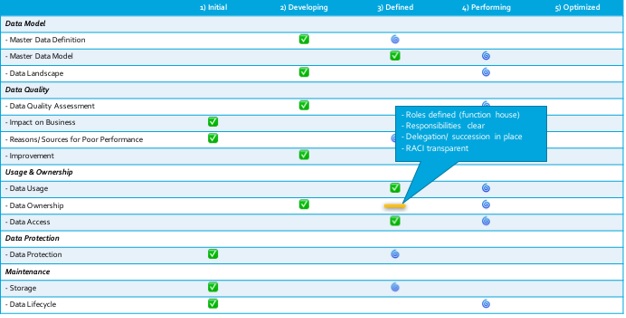
Op basis van de uitkomsten van het assessment wordt er gekeken welke gewenst level het beste is voor de organisatie. Per proces of onderdeel zijn verschillend levels toepasbaar indien gewenst. Dit zorgt voor een duidelijke strategieontwikkeling en het identificeren van concrete stappen om het gedefinieerde verschil te overbruggen. Zorg ervoor dat deze stappen realistisch en transparant zijn voor de organisatie. Dit brengt vertrouwen en goodwill voor de gebruikers die daarmee de initiatieven sneller accepteren.
Het bereiken van het gewenste niveau is zeker niet het eindstation. Het onderhouden en bijhouden van data is een continu proces en wanneer disciplinair uitgevoerd, minder moeite kosten. Probeer ook niet het wiel opnieuw uit te vinden, er zijn meer dan genoeg goede bestaande oplossingen de het mogelijk maken om naar het gewenste level te bereiken.
Voor elk data-element is een data-eigenaar nodig. Dit is iemand uit de organisatie die vanuit zijn of haar rol veel weet van het data-element. Bijvoorbeeld Marketing is verantwoordelijk voor Producten, Sales voor Klanten. De data-eigenaar bepaalt de mogelijke standaardwaarden en definities. Deze data-eigenaren documenteren deze standaarden die daarmee de basis vormen voor het verbetertraject.
Trends: nieuwe technieken en oplossingen
Voor het bereiken van de gewenste datakwaliteit, zijn meerdere oplossingsrichtingen mogelijk. Traditioneel wordt veel tijd en effort gestoken in het schoon krijgen en houden van de data in bronsystemen. Dit is een tijdrovende en (arbeids-)intensieve activiteit en roept door de lange doorlooptijd additionele datakwaliteit issues op.
Met de komst van nieuwe technieken en software is het mogelijk een groot deel van het menselijk werk te vervangen. Machine Learning (ML) en Artificial Intelligence (AI) leveren goede algoritmen en methodieken om de data schoon te maken en te houden. Daarmee wordt de menselijke factor voor een groot deel uitgeschakeld in het schoon maken en houden van data, wat minder kosten tot gevolg heeft en een hogere productiviteit per medewerker.
Een andere trend is dat de gebruikers niet kunnen en willen wachten op IT. De vraagstukken die gebruikers stellen, veranderen sneller dan IT bijbeent en dit zorgt ervoor dat veel IT-oplossingen al achterhaald zijn bij een go-live. Dit wordt opgelost door een “self-service” model te implementeren. IT draagt de verantwoordelijkheid voor het opslaan van data, maar ook de initiële data integratie van verschillende bronsystemen (zoals verschillende ERP, CRM of APS-systemen) en biedt dit aan als een “platform” aan richting de gebruikers. Deze gebruiker heeft de vrijheid additionele databronnen toe te voegen (denk hierbij aan online/ externe data of CSV-bestanden). Op deze uiteindelijke dataset worden data-analyses gemaakt en uiteindelijk gevisualiseerd om het “data verhaal” te vertellen. Dit is een trend waarbij IT en gebruikers meer gaan samenwerken.
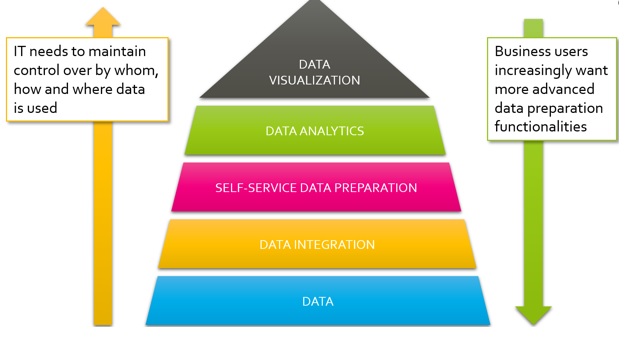
De toegevoegde waarde voor het Plannings- & Forecastproces
Waar zit de toegevoegde waarde van datakwaliteit voor het plannings- en forecast proces binnen een organisatie? Onderstaande overzicht laat zien wat goede data toevoegt aan dit proces.
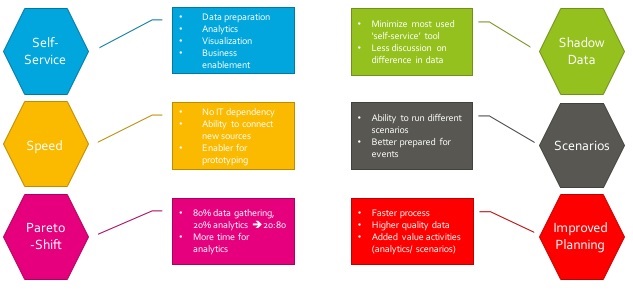
? Self Service: de verhoogde kwaliteit van de data geeft de gebruiker van deze data meer vertrouwen in de juistheid van de getallen. Hiermee wordt ‘self service’ een feit, waarmee de dataconsument zelf zijn rapporten maakt en analysis uitvoert, zonder de tussenkomst van IT.
? Speed: de verhoogde snelheid van handelen door een goede kwaliteit van data. Minder handeling om de juiste data te verkrijgen, waardoor de dataconsument sneller zijn rapporten en analyses maakt en daarmee sneller reageert op de veranderingen in de wereld.
? Pareto-Shift: nu zijn veel dataconsumenten veel tijd kwijt aan het verzamelen, koppelen en schonen van data. Als de data al op een minimaal kwaliteitsniveau wordt aangeboden, heeft deze dataconsument veel meer tijd voor het maken van analyse
? Shadow data: als de data niet wordt vertrouwd door de gebruikers, ondernemen zij zelf acties om deze wel op het juiste niveau te krijgen. In de meeste gevallen wordt dit m.b.v. Excel uitgevoerd, wat tot extra uitdagingen binnen de organisatie leidt. Waarom is er geen consistent beeld van de laatste stand van zaken, waarom heeft Sales een ander getal t.o.v. Operations? Met de juiste datakwaliteit is het ecosysteem van Excel-rapportages overbodig.
? Scenario’s: het uitvoeren van scenario’s is binnen veel bedrijven lastig uit te voeren. Vaak zijn de mensen betrokken in het planningsproces al tevreden als vlak voor de deadline een definitief plan opgeleverd wordt. Enige tijd om scenario’s door te rekenen is dan niet meer mogelijk. Terwijl het maken van scenario’s een organisatie veel beter in staat stelt om te reageren op toekomstige veranderingen.
? Improved Planning: met de juiste datakwaliteit wordt de snelheid van handelen enorm verhoogd en stelt het de dataconsumenten in staat meer activiteiten uit te voeren die echt waarde toevoegen aan het plannings- en forecastproces.
Concreet: vervolgstappen
Is het verhogen van de datakwaliteit eenvoudig en snel te realiseren? Wordt het schonen van data als een kernactiviteit beschouwd binnen bedrijven? Bij veel bedrijven worden deze vragen met een volmondig ‘NEE’ beantwoord. Vaak omdat de perceptie bestaat dat het schonen van data een lastig en tijdrovend proces is. Maar met de laatste technologie en onderstaand stappenplan is dat geen probleem meer.
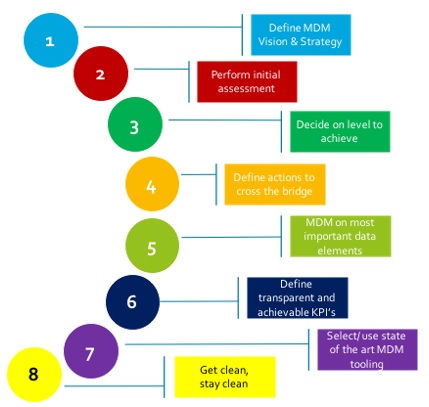
Als organisatie is het belangrijk na te denken hoe om te gaan met data en wat het gewenste kwaliteitsniveau moet zijn. Een eerste assessment geeft inzicht geven in de huidige status, waarna de organisatie (per data-element) een gewenst niveau definieert. Het verschil tussen huidig en gewenst niveau resulteert in acties om het gewenste niveau te realiseren. Masterdata management is op de belangrijkste data elementen van toepassing, waarbij (functionele) eigenaren benoemd worden die deze kwaliteit bewaken.
Om de kwaliteit te verankeren in de dagelijkse operatie, is het belangrijk transparante KPI’s te definiëren en periodiek te rapporteren. De juiste programma’s (denk daarbij zeker aan nieuwe, vaak Cloud-gebaseerd platformen met geïntegreerde AI en ML) neemt de organisatie veel handmatig werk uit handen door processen te automatiseren. Deze programma’s leveren dan ook een belangrijke bijdrage aan een continu verbeterproces, waarbij de datakwaliteit op een steeds hoger niveau komt te liggen.
Auteurs
Jurgen Maas (jurgen.maas@eyeon.nl) is een zeer ervaren consultant (EyeOn) op het gebied van implementeren van Planningsapplicaties en Data Management. Jan Veerman (jan.veerman@eyeon.nl) is Partner bij EyeOn en heeft veel ervaring op het gebied van implementeren van Planningsapplicaties en Data Management.
EyeOn is een toonaangevend adviesbureau op het gebied van Planning & Forecasting. Bij veel van onze projecten is data en de datakwaliteit een aandachtsgebied, waardoor we veel ervaring hebben opgebouwd in het verbeteren van deze kwaliteit. We kijken daarbij voortdurend naar nieuwe technieken en tools ter ondersteuning van de Planning & Forecasting processen.








Markt Update



Personalia



Whitepapers



Vragen over adverteren?

Kan ik je van dienst zijn met een toelichting of advies? Bel of mail gerust. Ik neem graag de tijd voor je.
Daan Commandeur
Partner Manager