Hoe realiseer je een snellere maandafsluiting met Data Analyse?

Veel organisaties zoeken naar manieren om de maand-, kwartaal- of jaarafsluiting te versnellen. De oplossing heet Data Analyse.
Het versnellen van de afsluiting is vaak makkelijker gezegd dan gedaan. Naast het versnellen van de afsluiting, speelt de kwaliteit van de data een belangrijke rol. Hoe doe je dat als een bedrijf duizenden werknemers over de hele wereld verspreid heeft die verantwoordelijk zijn voor het invoeren van miljoenen transacties? Data Analyse kan helpen bij het versnellen van de afsluiting. Hiervoor heb je twee manieren: de symptomen bestrijden of het probleem bij de wortels aanpakken.
Stucturele Oplossing
Laten we eerst kijken naar de structurele oplossing. Hier gaat het om het vinden van onjuiste, niet complete of niet tijdige transacties voor de periodeafsluiting. De meeste organisaties hebben een ordersysteem en een financieel systeem. Een logische optie is om een validatieroutine bij de invoer in het ordersysteem op te nemen. Omdat financiële details pas later bekend worden, is een deze oplossing moeilijk toepasbaar.
Een tweede oplossing is het toevoegen van een controlemechanisme in de interface tussen het ordersysteem en het financiële systeem zodat alleen geldige transacties doorkomen. De regels van dit controlemechanisme kunnen niet te streng zijn omdat er altijd uitzonderingen zijn. Een derde oplossing is om verdachte transacties gewoon door te laten gaan van het ordersysteem naar het financiële systeem, om vervolgens business controllers de automatisch gevonden verdachte transacties te laten controleren.
Data Analyse als onderdeel van de maandafsluiting
Als het niet mogelijk is om het bovenstaande te implementeren is het ook mogelijk om een schatting te maken van de daadwerkelijke opbrengsten op basis van historische data. Een eis daarbij is dat een dergelijke systematiek wel op detailniveau gebeurt. Anders is geen reconciliatie mogelijk en kunnen accountants niet controleren wat er gebeurt. Als de schattingen en daadwerkelijke omzet naadloos op elkaar aansluiten kun je de boeken vervolgens sluiten met cijfers gebaseerd op de schattingen. De grafiek toont een voorbeeld van een project waar we aan gewerkt hebben, de daadwerkelijke bedragen zijn aangepast.
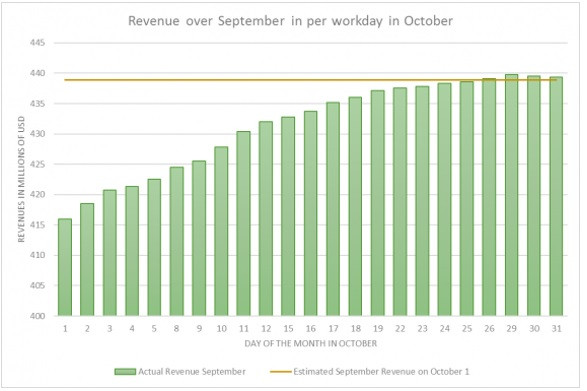
Figuur 1: Door missende gegevens worden de boeken voor september pas eind oktober afgesloten. Met behulp van een nauwkeurige voorspelling kan dit vier weken naar voren gehaald worden.
Er zijn drie processen in het maken van voorspellingen.
Proces 1: Automatisch modellen genereren
Creëer wiskundige modellen die de omzet en kosten schatten op basis van historische data. Het automatisch schatten van modellen heeft vele voordelen. Het eerste voordeel is dat de kosten voor het inhuren van dure data scientists veel lager zijn. Het tweede voordeel is dat het proces controleerbaar wordt. Het derde voordeel is dat meerdere voorspelmethoden simultaan gebruikt kunnen worden voor het schatten van de omzet. Het kan bijvoorbeeld voorkomen dat de ene methode de ene keer de beste voorspellingen oplevert en een andere keer de andere methode. Op deze manier kan je bijvoorbeeld structuurmodellen en datamining algoritmes met elkaar combineren.
Proces 2. Automatisch transacties voorspellen
Het tweede proces is het voorspellen van toekomstige transacties met de uit proces 1 geschatte modellen. Dit kan ook geavanceerder. We schatten meerdere modellen tegelijkertijd. In de volgende tabel staan 3 voorbeelden van modellen.

Een eenvoudig voorbeeld: stel een transactie heeft een daadwerkelijke omzet van 1.000 dollar. Als alle drie de methoden de omzet boven de 9.000 dollar voorspellen, is de transactie verdacht. Met een beslissingsboom kunnen we, op basis van eigenschappen van de transactie, de voor die situatie beste model selecteren. Dit is nodig omdat ieder model een vereenvoudiging is van de werkelijkheid en dus de beperkingen kent.
Proces 3: Lerende voorspellingen
Stel dat de marktcondities voor een bepaalde regio of product veranderen. Bijvoorbeeld door veranderingen in wisselkoersen, seizoenseffecten, nieuwe concurrentie, etc. Hierdoor gaan voorspellingen afwijken. Als deze afwijkingen langere tijd aanhouden, wordt proces 1 automatisch aangestuurd.
Andere voordelen
Deze methoden helpen ook mee op andere gebieden:
– Revenue managers krijgen real-time inzichten in de veranderingen van marktcondities en kunnen daar direct op reageren. Zonder geavanceerde technieken kan het maanden duren voordat je bewust wordt van deze veranderingen.
– Vuistregels van experts uit de praktijk kunnen gebruikt worden om de modellen te verbeteren. Andersom kunnen modellen ervoor zorgen dat vuistregels herzien worden.
– De werknemers die dit werk doen worden aangemoedigd om de kwaliteit van de data in orde te houden, een belangrijke competentie in de tijd van Big Data.
Is dit science fiction?
Nee dat is het niet. Wij hebben een systeem ontwikkeld dat 12.000 modellen automatisch schat om de inkomsten te voorspellen van een transportbedrijf. We schatten de inkomsten op dag 2 van de sluiting en vergelijken dit met de daadwerkelijke omzet 40 dagen na de sluiting. Deze verschillen minder dan 0,2 procent. Microsoft brengt binnenkort SQL Server 2016 op de markt. Daarin is R geïntegreerd in hun platform. Hierdoor wordt met name proces 1 en 3 nog veel gemakkelijker uit te voeren.
Peter de Reus is directeur van Decisive Facts en richt zich op betere besluitvorming en het beter benutten van beschikbare data. Peter heeft ruim 20 jaar ervaring met data analyse toegepast bij zorginstellingen, corporaties, financiële instellingen en transport en logistiek.





Markt Update

Net nu veel ondernemingen staan...

Online bank BUUT gaat concurreren...

De Europese Unie zorgde sinds...
Personalia

De kracht van overzicht en...

De opvolger van Klaas Knot...

Van Loon was bijna twee...
Whitepapers

Uit onderzoek onder 251 Nederlandse...

Van inkoop tot betaling: grip...

AI luidt een nieuw tijdperk...
Vragen over adverteren?

Kan ik je van dienst zijn met een toelichting of advies? Bel of mail gerust. Ik neem graag de tijd voor je.
Daan Commandeur
Partner Manager