Excel: Tabellen for sale. Maar welke moet ik kiezen?
Een serie blogs over Excel en Power BI.
BLOG – In deze serie bespreek ik de derde van het vijflagen van Business Intelligence model: delen, visualiseren, analyseren, voorbereiden en verbinden. Analyseren in Excel gaat best ver. Het omvat niet alleen het berekenen van getallen maar ook de manier waarop je tabellen in jouw model gebruikt.
 Door Henk Vlootman, adviseur, trainer, spreker en auteur, en topspecialist op het gebied van Microsoft Power BI en Power Query.
Door Henk Vlootman, adviseur, trainer, spreker en auteur, en topspecialist op het gebied van Microsoft Power BI en Power Query.
In de professionele Excel en Power BI-wereld wordt informatie (lees: gegevens) opgeslagen in tabellen. Ik ga uit van de twee meest populaire varianten van het vastleggen van gegevens in tabellen: de platte database, zoals die wordt gebruikt in de klassieke Excel omgeving en de relationele database, die je in de wereld van Power Pivot terugvindt. Wat misschien ook verwarrend is dat de begrippen tabel en database ogenschijnlijk door elkaar worden gebruikt. Houd als vuistregel vast dat een platte database slechts een tabel en een relationele database altijd een collectie van meerdere tabellen bevat.
Iedere tabel kent twee dimensies: de rij en de kolom. Wat flauw, maar die dimensies creëren twee contexten: een kolom en een rij context. De kolom context geeft aan wat je in de kolom verwacht en de rij context geeft de relatie tussen de kolommen van die tabel weer. Hoe dat werkt zie je in de afbeelding.
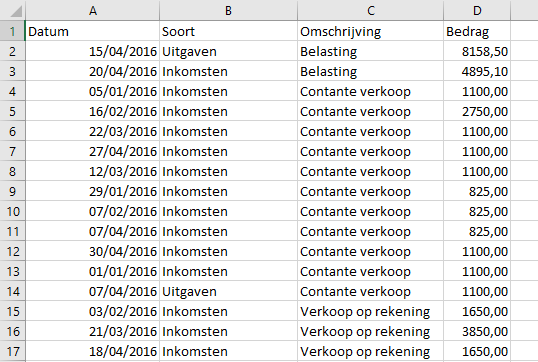
In de eerste kolom heet Datum (die eerste rij wordt overigens header, of in het Nederlands Koprij, genoemd en “omschrijft” wat je in de kolom verwacht) en daar staan – ook flauw, maar wel essentieel – datums in. De kolommen Soort en Omschrijving bevatten teksten en de laatste kolom Bedrag getallen. Iedere kolom in een tabel heeft zijn eigen kolom context. Kijk je nu naar de rij, bijvoorbeeld rij 2, dan vormt de onderlinge posities binnen de tabel een “omschrijving” van de gebeurtenis. Dus op 15 april is aan de belasting €8.185,50 betaald. Dit wordt de rij context genoemd, maar ook de namen record of transactie worden hiervoor gebruikt. Snap je het nog?
Bij het ontwikkelen van de eerste spreadsheets werden werden verschillende functies aan het rekenblad toegekend. Lotus 1-2-3, de killer app in de jaren 80 en 90 van de vorige eeuw bijvoorbeeld, had een bedoeling met de toevoeging 1-2-3. De nummers slaan namelijk op drie functies, die toen de basis van een revolutie vormden: spreadsheet, database en grafieken. Laat ik nu het geheim maar verklappen, de database, tabel of bereik (of hoe je het noemen wilt) toen en nu in de klassieke Excel omgeving behoort tot de categorie platte databases. Zoals eerder gezegd bestaat de platte database uit een slechts een tabel.
Bekijk opnieuw even afbeelding 2. Dat is een goed voorbeeld van een platte tabel. Misschien weet je het al of heb je het al gezien, maar deze tabel heeft een nadeel in de kolom context. Technisch heet dit fenomeen redundantie, maar in gewoon Nederlands betekent het dat gegevens meerdere keren voorkomen. Je ziet bijvoorbeeld de omschrijving “Verkoop op rekening” al drie keer in de afbeelding staan. ‘Niets aan de hand’ hoor ik je zeggen, ‘Excel werkt toch al decennia lang prima op deze manier’.
De Maar komt als je gegevens gaat toevoegen of wijzigen. Als je de omschrijving niet dodelijk consequent gebruikt – bijvoorbeeld je voert “Verkoop rekening“ in -, dan is het voor ons gebruikers, gezegend als we zijn met een creatieve mind, geen probleem. We lezen we wat er staat en maken onze eigen interpretatie en combineren automatisch beide omschrijvingen als een en dezelfde omschrijving. Helaas, zo niet voor computers. Voor computers zijn het echt twee verschillende gegevens. Ga je hiermee rekenen, dan klopt het resultaat helaas niet.
Een ander probleem is als de omschrijving je niet bevalt. Voor “Contante verkoop” wil je bij voorbeeld de omschrijving “Verkoop in winkel” hebben. Handmatig vervangen gaat best als het een paar regels zijn. Maar zijn het duizenden rijen, dan vertrouw je als snel op de functie “Zoek en Vervang”. Controle op het resultaat wordt dan wel erg lastig.
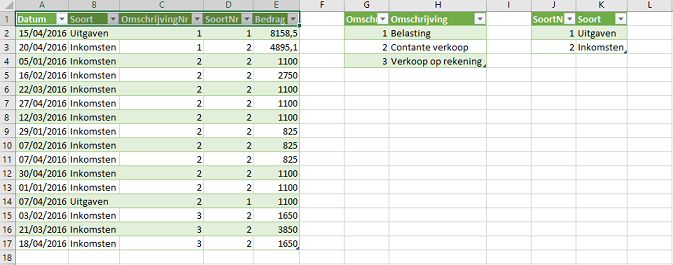
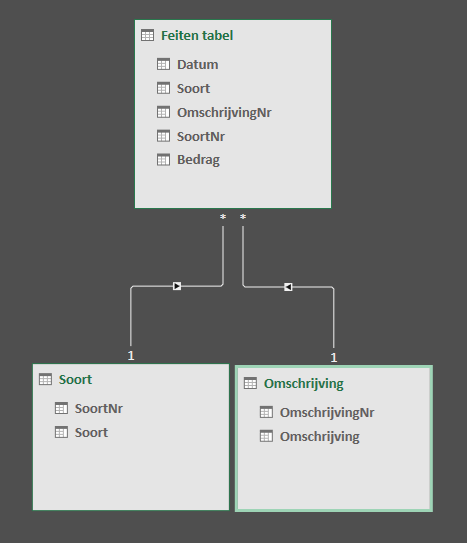
Al in 1970 is een begin gemaakt met het concept van een relationele database. Dit concept wordt gebruikt in Power Pivot en is de defacto standaard voor het professioneel opslaan van gegevens. Wat is het verschil met de platte database? Nu, de kolom context wordt uit elkaar getrokken en in verschillen de tabellen geplaatst. In afbeelding 3 zie je dat er drie verschillende tabellen zijn ontstaan. Je hebt de originele tabel, maar in de kolom Soort en Omschrijving zie je getallen staan. Daarnaast zijn er twee andere tabellen gemaakt. Daar zie het getal met de omschrijving. Tussen de originele tabel (ook wel feiten tabel genaamd) en de beide andere tabellen (ook wel dimensie of filter tabel genaamd) zijn relaties gelegd (zie afbeelding 4). Iedere omschrijving komt maar een keer voor. Wil je een omschrijving aanpassen, dan hoef je maar een keer in de dimensie tabel die actie uit te voeren en de nieuwe naam wordt in alle rijcontexten getoond.
Het gaat nog verder dan dit voorbeeld. Wil je in een Excel bereik nieuwe gegevens toevoegen, dan gebruikt de een (verticaal) zoekfunctie. Net als in een relatie heb je een kolom waar je op zoek. De inhoud van beide kolommen moet gelijk zijn. Dus nummers of (gelijke) omschrijvingen. Bij een platte database wordt de tabel steeds meer voorzien van kolommen. Bij relationele databases is het mogelijk dat in de rijcontext er meerdere gegevens opgenomen zijn. Dat zie je bijvoorbeeld in afbeelding 5, waar de tabel Omschrijving is uitgebreid. Je bent dus veel efficiënter aan het omgaan met je gegevens in een relationele database.

Wat is nu de conclusie van deze blog? Uiteindelijk is Power Pivot in Excel een logische vernieuwing in Excel, maar het verandert de traditionele manier van werken, waarmee de Excel gebruiker maar al te goed bekend is. En dat is dan de Achilleshiel van Power Pivot. Berekeningen in Power Pivot zijn namelijk anders van aard dan berekeningen in de traditionele manier van berekeningen in Excel. En dat werp een stevige drempel op voor de traditionele Excel gebruiker.
Blogs in deze serie:
- Excel: Tabellen for sale. Maar welke moet ik kiezen?
- Excel: De kunst van rij in kolom berekeningen
- Explosieve kracht in een cel: aggregaat berekeningen
- De liefdesverklaring van Power Pivot: relaties
- De echte waarde van Power BI
- Schema first of data first? Maar waar is je data?
- Visualiseren, de kunst van het verleiden (1)
- Low-code of no-code, de weg naar de toekomst (1)
- Low-code of no-code, de weg naar de toekomst (2)
- Controles, levensbloed voor je model (1)








Markt Update



Personalia



Whitepapers



Vragen over adverteren?

Kan ik je van dienst zijn met een toelichting of advies? Bel of mail gerust. Ik neem graag de tijd voor je.
Daan Commandeur
Partner Manager