De analysetechnieken van Big Data

Zijn de methoden en technieken die controllers tijdens hun studie leerden nog wel relevant nu organisaties in een omgeving werken die inmiddels veel dynamischer en complexer is? In dit eenentwintigste deel van de serie staat wederom kwaliteitsverbetering centraal, waarbij dit keer wordt ingezoomd op technieken om Big Data te analyseren.
Het eerste artikel over Big Data vindt u hier: De rol van de controller bij Big Data
Het gebruik van Big Data stelt een organisatie in staat de kwaliteit van de bedrijfsvoering te verbeteren en daarmee te bewerkstelligen dat zij ook in de toekomst waardevol blijft voor de stakeholders. Maar hoe pas je Big Data toe? In dit artikel worden deze vragen beantwoord.
Allereerst wordt een het onderstaande figuur getoond dat ontwikkeld is door Information Builders, een toonaangevende softwareproducent op het gebied van (onder meer) business intelligence. Het plaatje maakt inzichtelijk welke vormen van Big Data-analyses er zijn en wat hun meerwaarde is.
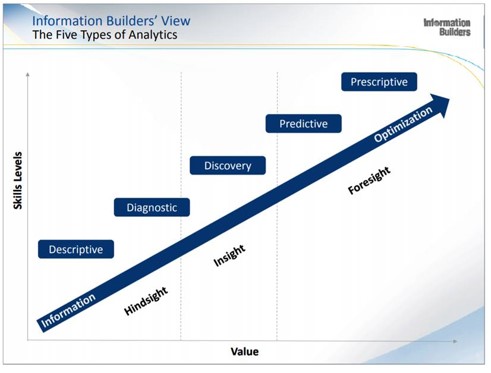
Big Data, het woord zegt het al, bestaat uit de enorme hoeveelheid gegevens die een organisatie tot haar beschikking heeft. Een organisatie kan gebruik maken van dat uit de eigen administratie, kranten- en Facebookberichten, informatie van brancheorganisaties, beurskoersen en weerberichten, noem maar op. In die berg aan gegevens zitten vast zaken die interessant zijn voor de bedrijfsvoering. Maar hoe ontsluit je die gegevens en hoe bewerk je ze tot waardevolle informatie? Als u niet weet waarnaar u op zoek bent, zult u niets vinden, dus het begint met het stellen van de juiste vragen! Pas als bekend is waar u naar op zoek bent, is het zinvol de zoektocht te starten.
De vraagstelling heeft immers grote invloed op de aanpak en het vereiste kennisniveau van de onderzoeker. Een voorbeeld. Stel, u bent controller bij een verzekeraar en u merkt dat er in februari 2018 voor een hoog bedrag aan schadeclaims is ingediend. U vraagt zich af of het aantal claims c.q. de hoogte per claim uitzonderlijk is. De onderzoeker past dan beschrijvende (descriptive) statistiek toe en bepaalt bijvoorbeeld het gemiddelde bedrag per claim en stelt vast in hoeverre dat afwijkt van het gemiddelde over een aantal jaren. Hulpmiddelen bij dergelijke berekeningen zijn bijvoorbeeld Excel en SPSS. Er is meestal weinig statistische kennis nodig om dergelijke analyses uit te voeren.
Vraagt men zich in de organisatie echter af waardoor het hoge bedrag aan claims wordt veroorzaakt, dan wordt het al een stuk lastiger. De weersomstandigheden kunnen een rol spelen (er waren die maand stormen en het was uitzonderlijk koud), maar ook de toegenomen bedrijvigheid door het gunstige economische tij kan een oorzaak zijn. En misschien zijn er nog wel andere oorzaken, of is er sprake van toeval. Om dat te achterhalen, moet de onderzoeker over meer statistische kennis beschikken. Zo kan er gezocht worden naar de samenhang tussen verschillende variabelen, wat bekend staat als de correlatie. Dat is iets anders dan een oorzaak-gevolgrelatie, maar uit nader onderzoek kan vervolgens wel blijken dat er sprake is van een causaal verband.
Dat gebeurde bijvoorbeeld aan het begin van de twintigste eeuw, toen ontdekt werd dat veel longkankerpatiënten ook rookten. Pas later werd vastgesteld dat tabak kankerverwekkend is. De onderzoeker zoekt dan naar verbanden tussen variabelen. Er wordt dan regressie-analyse toegepast, waarbij vastgesteld wordt wat de relatie is tussen bijvoorbeeld het aantal rokers in een land en het aantal kankerpatiënten. In hoeverre dat verband klopt kan bepaald worden met instrumenten om de correlatie te bepalen, zoals het vaststellen van de coëfficiënt van determinatie (R2), de t-waarde en de Durbin-Watson statistic als verondersteld wordt dat een bepaald verschijnsel met meerdere zaken in verband staat. Ook voor dergelijke berekeningen bieden SPSS en bijvoorbeeld Excel mogelijkheden, maar zowel het toepassen van de technieken als de interpretatie van de uitkomsten vereist al veel statistische kennis.
Als de verzekeraar wil weten welke schadeclaims er in juni 2018 kunnen worden verwacht, dan moeten behalve die hierboven beschreven stappen ook extra statistische functies worden ingezet. Er is dan immers sprake van voorspellende (predictive) statistiek, dus de waarnemingen uit het verleden moeten op een verantwoorden manier worden geëxtrapoleerd. Dat is om verschillende redenen lastig…
Ten eerste is het verband tussen verschijnselen niet altijd lineair. Zo is het extra schadebedrag van een stijging van de windkracht van niveau 4 naar 5 waarschijnlijk veel minder groot dan van 10 naar windkracht 11. Ten tweede is de correlatie vaak niet 100%. Als het bijvoorbeeld van vrijdag op zaterdag vriest is de blikschade de volgende dag wellicht geringer dan wanneer het van maandag op dinsdag vriest, omdat waarschijnlijk veel meer mensen op dinsdag al vroeg de weg op moeten dan op zaterdag. Er zijn dus soms meer aspecten die een rol spelen, zodat geen enkelvoudige, lineaire regressie kan worden toegepast. De onzekerheid of de voorspellingen dan wel kloppen, neemt hierdoor duidelijk toe. Anderzijds is het veel interessanter te weten wat de organisatie in de toekomst te wachten staat dan slechts inzicht te hebben waarom verschijnselen zich in het verleden hebben voorgedaan. Voorspellende statistiek kan dus zeer waardevol zijn als deze juist wordt toegepast.
De nieuwe vraag die gesteld wordt zou ook kunnen luiden: hoeveel mensen hebben we in juni 2018 nodig op de afdeling die schadeclaims afhandelt? Er is dan geen sprake van voorspellende (predictive) maar normatieve (prescriptive) statistiek. Nadat een norm voor de afhandelingstijd per soort claim is vastgesteld – descriptive statistiek kan daar bij helpen – kan vervolgens de personele bezetting voor de afdeling worden berekend door het te verwachten aantal claims te vermenigvuldigen met deze normtijden.
Big Data geeft overigens veel meer mogelijkheden dan hierboven beschreven. Hieronder vindt u een aantal van die technieken toegepast die vooral tot inzicht in tal van ontwikkelingen leiden.
Vraagstelling: wie frauderen er waarschijnlijk?
U gaat dan opzoek naar data (in jargon: data mining) over uitzonderingen. U zoekt uitbijters, dus afwijkende, opvallende scores. Bijvoorbeeld tandartsen die veel vaker een dure behandeling uitvoeren dan gemiddeld of verzekerden die vaak declareren. En fiscale rechercheurs in overheidsdienst zoeken mensen met een bescheiden fiscaal inkomen die toch een heel dure auto aanschaffen of hoge bedragen overboeken naar anderen. Deze techniek – outlier detection genoemd – kan helpen bepaalde mensen of groepen in het vizier te krijgen waar nader onderzoek naar gedaan wordt.
Welke polishouders kan een verzekeraar het beste benaderen voor een voorlichtingsbijeenkomst om de leefstijl te verbeteren?
Verzekeraars doen steeds meer aan preventie, maar bij welke klanten heeft dat het meeste zin? Bij rokers met overgewicht, of is het uiteindelijke effect bijvoorbeeld groter om gezonde vijftigers uit te nodigen? Zodra gezondheidswetenschappers (op basis van Big Data….) hebben vastgesteld welke kenmerken mensen hebben die gemotiveerd zijn de adviezen over te nemen, kan de data scientist aan de slag met het clusteren van de groepen klanten die aan deze kenmerken voldoen, zodat de juiste mensen uitgenodigd kunnen worden voor een dergelijke bijeenkomst. Voor dat clusteren bestaan allerlei statistische technieken en programma’s.
Welke (potentiële) klanten kan de verzekeraar het beste benaderen om een verzekering te verkopen?
De data scientist gaat dan op zoek naar associaties. Zo zou bijvoorbeeld kunnen worden vastgesteld dat mensen die een caravan kopen en laten verzekeren ook open staan voor het afsluiten van een doorlopende reisverzekering. Dat inzicht zorgt ervoor dat het geld dat aan marketingcommunicatie wordt besteed veel effectiever kan worden ingezet.
In welke risicocategorie valt een klant die een arbeidsongeschiktheidsverzekering wil afsluiten?
De hoogte van de verzekeringspremie is afhankelijk van het risico dat de verzekeraar loopt. Hoe meer risico, des te hoger de premie. Het is daarom belangrijk vast te stellen wat de kans is dat er moet worden uitgekeerd. Op basis van Big Data wordt er daarom een model ontwikkeld dat het mogelijk maakt om het risicoprofiel van een potentiële klant te bepalen. Deze datamining techniek heet classificatie.
Om de bovenstaande analyses uit te voeren, moet meestal gebruik gemaakt worden van zowel gestructureerde als ongestructureerde gegevens. Met gestructureerde data worden gegevens bedoeld die volgens een vast format zijn vastgelegd. Dat geldt bijvoorbeeld voor financiële gegevens die in de boekhouding zijn opgenomen en naam, adres en woonplaatsgegevens die in het adresbestand staan vermeld. Ongestructureerde gegevens zijn daarentegen willekeurige tekstberichten in boeken, kranten en bijvoorbeeld op social media, cijfers uit Excel of andere bestanden en dergelijke.
Voor echt waardevolle inzichten moeten de gestructureerde en ongestructureerde data met elkaar in verband worden gebracht. Dat lukt echter meestal niet zonder dat hier speciale softwaretools bij gebruikt worden, zoals Hadoop (open source), Cloudera (betaalversie van Hadoop), MongoDB en bijvoorbeeld Hive. Deze tools stellen de gebruikers in staat gegevens op te slaan, te raadplegen en bijvoorbeeld te presenteren in grafieken. Het is overigens ook mogelijk om als organisatie ook een eigen datawarehouse te creëren, waarin zowel de eigen CRM en ERP-systemen zijn opgenomen evenals externe bronnen, om die vervolgens te combineren.
Om Big Data te analyseren zijn algoritmen nodig, dus instructies. Concreet betekent dit dat de onderzoeker de “computer” vertelt waar deze naar op zoek moet. Als een zorginstelling bijvoorbeeld wil weten wat de verklarende factoren zijn voor een hoog ziekteverzuim bij het personeel, dan kan de Big Data analist op zoek gaan naar deze oorzaken. Stel dat het management vermoedt dat zaken als fysiek zwaar werk, leeftijd, het hebben van jonge kinderen en de mate van zelfsturing een rol spelen, dan kan geanalyseerd worden of deze verbanden echt bestaan. Dit is echter tijdrovend werk, vandaar dat er naar een slimmere aanpak is gezocht. Sommige Big Data analisten maken gebruik van machine learning. Bij deze manier van analyseren wordt vrijwel al het werk aan de computer overgelaten. Het is dus een vorm van kunstmatige intelligentie. Er zijn in principe twee vormen van machinaal leren. Bij de eerste vorm instrueert de mens de computer waar deze op moet letten.
Naarmate de computer meer inputgegevens krijgt, dus over een grotere hoeveelheid data kan beschikken, neemt de betrouwbaarheid van de gevonden verbanden toe, zodat voorspellingen steeds beter worden. Een andere mogelijkheid is de computer ál het werk te laten doen, met als doel alle mogelijke verbanden tussen datasets te vinden. Zo’n aanpak heeft als voordeel dat er nu ook onverwachte verbanden worden gevonden. Misschien zijn medewerkers die yoga beoefenen minder vaak ziek, terwijl mensen die hardlopen juist vaker absent zijn. Als dan een causaal verband kan worden vastgesteld, dan kan daar bij het personeelsbeleid rekening mee gehouden worden.
Er zullen echter ook verbanden worden vastgesteld die nietszeggend of onwaarschijnlijk zijn en die moeten eruit worden gefilterd omdat zij niet beleidsbepalend moeten zijn. Zo zou de computer een relatie kunnen vinden tussen de stand van de maan en het ziekteverzuim. Waarschijnlijk is dat verband puur toeval, maar de computer is (nog) niet intelligent genoeg om dat op te merken. Vooralsnog is er een mens nodig om dat te bepalen. Echter, de ontwikkelingen gaan snel. Vrijwel alle transacties op de financiële markten gaan computergestuurd en deze zijn gebaseerd op self-learning algoritmes, wat inhoudt dat de computer steeds de uitkomsten van haar eigen bevindingen evalueert door ze te vergelijken met de werkelijkheid en de verschillen gebruikt voor het maken van betere analyses en voorspellingen.
Drs. Theo van Houten en Luuk Roeling Msc. zijn beiden (hoofd)docent aan de opleiding Bedrijfseconomie van de Hogeschool van Arnhem en Nijmegen. Roeling werkte voorheen onder meer als Business Intelligence Specialist voor ABN Amro. Van Houten is naast hoofddocent management accounting ook onderzoeker bij het Lectoraat Financial Control. Tevens is hij onder meer (mede-)auteur van de boeken ‘Financial control van projecten’ en ‘Bedrijfseconomie in de praktijk’.








Markt Update



Personalia



Whitepapers



Vragen over adverteren?

Kan ik je van dienst zijn met een toelichting of advies? Bel of mail gerust. Ik neem graag de tijd voor je.
Daan Commandeur
Partner Manager