Kan data-analyse resultaat-manipulatie ontdekken?

Data-analyse geldt als een grote belofte, maar feit is dat het al lange tijd succesvol gebruikt wordt. De vroege gebruikers, doorgaans uit de academische wereld, zijn alweer een fase verder; ze hebben ook de mitsen en maren van data-analyse ondervonden en geleerd hoe er mee om te gaan. Met een bespreking van zo een data-analyse-project, waarin gezocht wordt naar een model om uit financiële rapportages signalen voor resultaat-manipulatie te ontdekken, wil ik potentie en beperkingen laten zien.
Door Rene Verbrugge
Zou het niet geweldig zijn als je met een rekenregel manipulatie kunt ontdekken? Dit project van de Canadees Beneish heet ‘The Detection of Earnings Manipulation’ (*1) en vergelijkt betrapte bedrijven met eerlijke bedrijven om te leren waarmee je manipulatie kunt ontdekken. Het heeft in Nederland weinig aandacht gekregen.
Het door Beneish berekende signaleringsmodel gebruikt acht kengetallen, die samengevat worden in een eindscore met de passende naam M-Score (Manipulation Score). Als men destijds (in 2001) de moeite had genomen het te gebruiken was de fraude bij Enron eerder ontdekt, want de M-Score signaleert de manipulatie correct.
1. Maar wat is manipulatie eigenlijk?
Dit treedt op als beslissers financiële rapportages of bedrijfsbeslissingen naar eigen inzichten bijsturen om:
– belanghebbenden te misleiden over de prestaties van het bedrijf of
– om contract-uitkomsten te beïnvloeden, die afhangen van financiële uitkomsten (zoals bank-convenanten).
Resultaat-manipulatie wordt ook wel winst-manipulatie of earnings management genoemd. Het treedt niet willekeurig op, maar er moet voldaan zijn aan drie voorwaarden;
a. de manipulator heeft een motief. Deze verwacht dus enig voordeel en de financiële prognose wijkt naar verwachting af van het ideaal of de eis,
b. er is een gelegenheid te manipuleren, terwijl de kans op ontdekking gering geacht wordt en
c. er zijn mogelijkheden tot manipulatie in de sfeer van operationele beslissingen of de verslaggeving.
Manipuleren kan – anders dan gedacht – ook door de winst te verlagen, zodat een ‘koekjestrommel’ wordt gevuld, waaruit in lastige tijden het resultaat opgepoetst kan worden.
Dat het fenomeen echt voorkomt blijkt ook uit het onderzoek van David Burghstahler en Ilia Dichev (*2). In kwartaalrapportages blijken veel meer kleine winststijgingen en veel minder kleine winstdalingen voor te komen dan je zou mogen verwachten.
2. Vijf kengetallen in de M-Score
Beneish gebruikte acht kengetallen om de M-Score te berekenen, maar hiervan zijn er maar vijf significant. Elk kengetal wordt vergeleken met het vorig jaar; het is dus een index. Hoe hoger de M-Score, hoe hoger de kans op manipulatie.
a. Index Debiteurendagen (DSRI)
Debiteurendagen = (Debiteurensaldo / Omzet) * 365
Ratio achter dit kengetal is dat verondersteld wordt dat het debiteurensaldo meebeweegt met de omzet als het kredietbeleid onveranderd blijft.
b. Index BrutoMarge (GMI)
BrutoMarge = (Omzet – Kostprijs Verkopen) / Omzet
Ratio achter dit kengetal is afnemende winstgevendheid te signaleren, wat een motief voor manipulatie kan zijn.
___________________________________________________________________________________
Topmanagers eisen financiële analyse voor al hun belangrijke beslissingen: overnames, financieringen, reorganisaties en investeringen. Signaleer sneller financiële risico’s en kansen. Volg de succesvolle training Financiële Analyse. Meld u hier aan.
___________________________________________________________________________________
c. Index Kwaliteit activa (AQI)
Kwaliteit activa = (Totale activa – vlottende activa – vaste activa) / Totale activa
De index meet toename van immateriele activa. Toename kan duiden op overmatige activering van kosten.
d. Index Omzet (SGI)
Groeibedrijven hebben vaak een hoge omzetdruk om groeidoelen te halen en een hoge financieringsbehoefte.
e. Index Accruals (TATA)
Accruals, er is helaas geen Nederlands equivalent, zijn alle verschillen tussen nettowinst en operationele cash-flow, dus wijzigingen in de activa en passiva op de balans die niet te herleiden zijn op de netto-winst (of -verlies). Denk aan overlopende posten, voorzieningen, ontrekkingen, investeringen en afschrijvingen.
Accruals-ratio = (Netto-winst voor bijzondere posten – Kasstroom uit operationele aktiviteiten) / Totale activa
Deze ratio signaleert het deel van de winst dat niet in contanten verdiend is.
3. Model om manipulatie te ontdekken valt tegen
Het berekende model is gebaseerd op een bedrijvenbestand van 74 manipulatoren en 2332 niet-manipulatoren. Als techniek is logistische regressie (wel/niet gemanipuleerd) gebruikt. Het model blijkt een nauwkeurigheid van slechts 37% te hebben. Dat is laag; er moeten dus meer oorzaken of indicators voor manipulatie zijn, maar de data daarvan hebben we niet.
Van de acht gebruikte ratio’s blijken slechts de vijf genoemde significant, d.w.z. voldoende van nul af te wijken.
De drempel in het model om als manipulator aangemerkt is een M-Score hoger dan – 1,78. Bij een score van -3 is een bedrijf dus geen manipulator, bij een score van -1 wel.
Hoe vaak kloppen classificaties als we met het model terugkijken? Van de manipulatoren wordt 26% niet opgemerkt en van de niet-manipulatoren wordt 14% ten onrechte als manipulator aangemerkt. Dat valt mee, maar het is niet nauwkeurig genoeg.
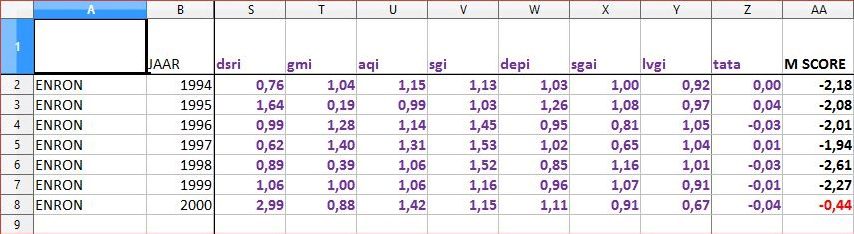
4. Enron wel gesignaleerd
Enron was een van de grootste verslaggevingsfraudes ooit. Zou het model dit gesignaleerd hebben? Ja, ondanks de lage nauwkeurigheid was Enron (zie tabel) door de mand gevallen. Waren de scores in 1994 t/m 1999 lager dan -1,78 en dus gunstig, in 2000 wees de score van -0,44 op fraude.
5. De mitsen en maren
Het berekende model kent beperkingen.
a. Het gaat alleen over beursgenoteerde bedrijven.
b. Het is alleen bedoeld om grote manipulaties te signaleren, de kleine blijven zeker onontdekt.
c. Het genereert veel valse positieven, namelijk 14% van 2332, dus 326. Deze moet je dus allemaal controleren, wat niet kan want je weet niet welke het zijn.
d. De nauwkeurigheid van de voorspellingen met het model is laag, de R2 is slechts 0,37
6. Kan data-analyse resultaat-manipulatie ontdekken?
De conclusie mag zijn dat het model niet goed genoeg is, ondanks de enorme inspanning voor
data-verzameling en berekening van de indicatoren. Voor een goede signalering van manipulatie met
financiele data zijn betere data nodig. Misschien leveren data over de bedrijfstak, de
eigendomsstructuur en de grootte een beter model op. Ook andere data-analyse-technieken, zoals een
classificatie-beslisboom, zouden onderzocht moeten worden.
Een data-analyse project kan dus interessante, nieuwswaardige uitkomsten opleveren, die desondanks
niet betrouwbaar genoeg zijn en dus onbruikbaar. Alle moeite voor niets?
Welke data zijn volgens jou nodig voor een goed model om resultaat-manipulatie te signaleren?
Drs. Rene Verbrugge is zelfstandig adviseur voor het MKB en auteur van het boek “Schep meer financiële ruimte om te ondernemen en zorg voor grip op uw werkkapitaal”.








Markt Update

Voor financieringsstructuren die risico’s hanteerbaar...

Het Amsterdamse kantoor heeft licenties...

Valutakosten zijn een bron van...
Personalia

Hij vervangt Victor van der...

Group Controller Remco Langewouters neemt...

Richard Doornbosch wordt in september...
Whitepapers

AI is geen toekomstmuziek meer...

Markten bewegen sneller dan ooit....

Als financial weet je genoeg...
Vragen over adverteren?

Kan ik je van dienst zijn met een toelichting of advies? Bel of mail gerust. Ik neem graag de tijd voor je.
Daan Commandeur
Partner Manager